昨天介紹了逐行解析 , 今天我們來說明另一個解析方法 逐字解析 吧 ~
逐字解析會需要經歷兩個步驟 , 才會變成像昨天一樣的 AST
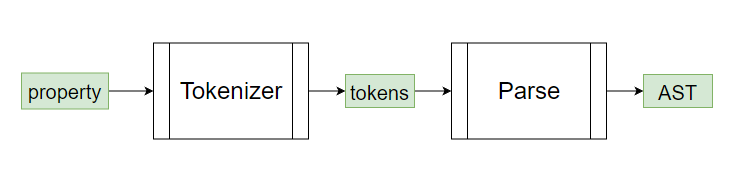
那經過 Tokenizer 後的 Token 陣列長什麼樣子呢 ?
舉個例子來說明好了:
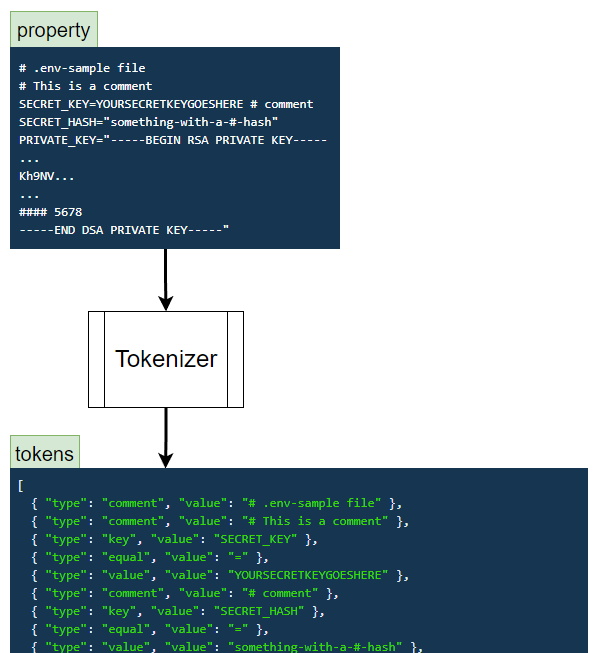
昨天的 .env-sample 檔案:
# .env-sample file
# This is a comment
SECRET_KEY=YOURSECRETKEYGOESHERE # comment
SECRET_HASH="something-with-a-#-hash"
PRIVATE_KEY="-----BEGIN RSA PRIVATE KEY-----
...
Kh9NV...
...
#### 5678
-----END DSA PRIVATE KEY-----"
經過 Tokenizer 處理後,會變成下面的 Tokens:
[
{ "type": "comment", "value": "# .env-sample file" },
{ "type": "comment", "value": "# This is a comment" },
{ "type": "key", "value": "SECRET_KEY" },
{ "type": "equal", "value": "=" },
{ "type": "value", "value": "YOURSECRETKEYGOESHERE" },
{ "type": "comment", "value": "# comment" },
{ "type": "key", "value": "SECRET_HASH" },
{ "type": "equal", "value": "=" },
{ "type": "value", "value": "something-with-a-#-hash" },
{ "type": "key", "value": "PRIVATE_KEY" },
{ "type": "equal", "value": "=" },
{ "type": "value", "value": "-----BEGIN RSA PRIVATE KEY-----\n...\nKh9NV...\n...\n#### 5678\n-----END DSA PRIVATE KEY-----" }
]
如下方圖片所示
明天我們將說明實作 Tokenizer 需要用的的工具 狀態機 
剛剛發現 龍哥今年的主題是 自製程式語言 ,本文應該會有部分主題與之相同的,
如果本文有解釋不清的部分,可以看龍哥的文章 (;´д`)ゞ

 ?
?
 iThome鐵人賽
iThome鐵人賽